py+bs4爬取河北白石山旅游者旅游相关信息
受人所托对河北白石山旅游者旅游相关信息进行爬取,原要求是使用一些行为数据计算得旅游者空间行为与旅游景观以及旅游环境容量,不明觉厉。需要用到白石山照片、照片拍摄时间(季节)、照片拍摄经纬度和行为轨迹等信息,当时我听到这种要求是很震惊的,上传到网上的照片都是经过处理的,且不说拍摄时间等信息被抹去,白石山就那么大,要经纬度emm有想法,后来得知还真有一个网站保留了这些信息,没错它就叫”六只脚”,好了,背景就是这些了,又到了快乐的搬砖时间。
软件环境及数据背景
pycharm-community-2020.2 + Anaconda3-2020.07-Windows-x86_64 + Python 3.7.9 + beautifulsoup4 4.9.1,爬取对象六只脚网站http://www.foooooot.com。
正文
为什么使用bs提取库?当然是因为简单容易上手啊,网上看点资料半小时应该就可以自己爬了,主要就四步:requests.get + re.compile + soup.find_all + re.findall,对付这种问题足够了,如果要深耕爬虫的话,还是要好好学下的。
好了,爬它!
主页爬取
首先当然是分析网页结构,在搜索框输入关键字”河北白石山”回车,看到即将要爬取的主页信息长这样(下面我说的主页都是值这个搜索结果页面,后面说的副页是指主页中的每篇文章点开进去的页面):
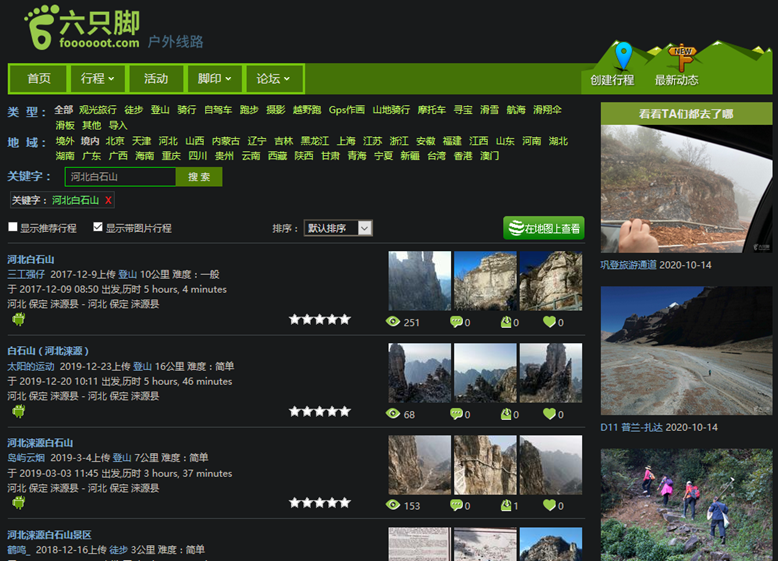
看起来还算友好,看看这个页面的HTML,定位到每篇文章摘要的地方:
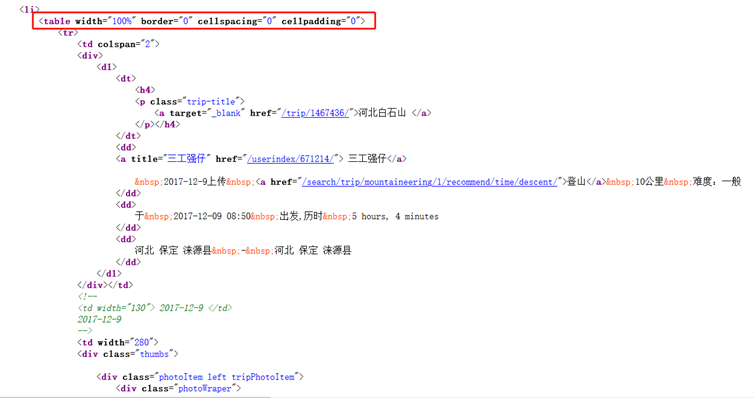
发现了每篇文章摘要格式化般的代码结构,每篇文章摘要都在下面这个盒子里面,很好。
<table width="100%" border="0" cellspacing="0" cellpadding="0">对比文章摘要信息和代码:
摘要

文字代码部分
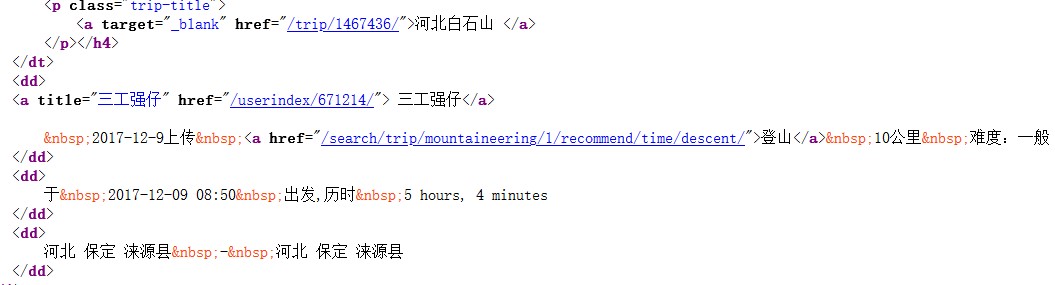
照片代码部分

貌似都很规矩,其实坑还不少,包括前面的盒子也高兴早了。
使用requests.get方法得到页面主页的HTML源码保存为全局变量html,这个就不多说了,开始关键的正则表达式,直接上代码
findPage = re.compile(r'<a href="(.+\n*)" target=".+\n*">') # 找到主页中各个副页文章链接
findTitle = re.compile(r'<a href=".+\n*" target=".+\n*">(.+\n*)</a>') # 找到游记题名
findName = re.compile(r'<a href=".+\n*" title=".+\n*">(.+\n*)</a>') # 找到文章作者昵称
findJourney = re.compile(r'</a>(.+)公里') # 找到作者行程里数
findStartTime = re.compile(r'于(.+)出发') # 找到作者旅游出发时间
findSpentTime = re.compile(r'历时(.+)\n\s+</dd>') # 找到作者旅游旅游时长
findImgSrc = re.compile(r'<img.*src="(.*)"\n*\s*title') # 找到展示图片连接,列表
datalist = [] # 每个游客信息为一项
pagelist = [] # 副页文章链接列表重点说下有坑的部分,浏览器看着这HTML代码还算干净,但要真按照这个来定规则超链接a标签将会什么也爬不到,后面选取一段摘要代码以字符串形式打印出来,会发现a标签长这样:
<a href="/trip/2021595/" target="_blank">白石山 </a>还有这样:
<a href="/userindex/231932/" title="野鹤
"> 野鹤
</a>而浏览器看见的是这样:
<a target="_blank" href="/trip/2021595/">白石山 </a>
<a href="/userindex/231932/" title="野鹤"> 野鹤</a>href和target位置对调了,并且还有一些莫名其妙的换行空格等,开始的时候没注意打印,就没爬到数据,因为规则不对。这次的爬取一共有247条文章数据,一共9个主页,每个主页30条文章摘要,最后第9 页7条,这么多也不知道那些文章格式有问题,所以有些规则为了避开这样的错误,也事先加上了换行符。datalist和pagelist都是列表,对应每格保存一篇文章摘要信息和一篇文章的连接。
哦,对了推荐一个正则表达式测试软件RegexBuddy,已经放到在文末的代码.zip了,挺好用的。
说下一个坑,附上代码:
for i in range(1, 10): # 以'河北白石山'为关键词搜索,检索结构9页
url = baseurl.replace('page_num', str(i))
print(url)
html = askURL(url)
soup = BeautifulSoup(html, "html.parser")
j = 1 # 主页中游客文章前面有一个与游客文章相同的盒子,避开
for item in soup.find_all('table', width="100%", border="0",
cellspacing="0", cellpadding="0"): # 找到每一个文章项
if j == 1:
j += 1
continue
data = []
item = str(item) # 转换成字符串
# print(item)
page = 'http://www.foooooot.com' + re.findall(findPage, item)[0] # 取得每个主页链接
pagelist.append(page)
title = re.findall(findTitle, item)[0]
data.append(title)
name = re.findall(findName, item)[0]
data.append(name)
journey = re.findall(findJourney, item)[0]
data.append(journey)
start_time = re.findall(findStartTime, item)[0]
data.append(start_time)
spent_time = re.findall(findSpentTime, item)[0]
data.append(spent_time)
imgs_src = re.findall(findImgSrc, item)
imgs_src = '\n'.join(imgs_src) # 将每个照片链接换行显示
data.append(imgs_src)
datalist.append(data)就是定义变量j的那个地方,这个变量j的作用就是,避开每个主页的第一个文章摘要盒子的前面那个盒子:

这熟悉的li和table,本来考虑用选择器的父子关系来避开的,想了一下觉得附近都长得太像了,不好操作,还是定义个变量j让它等于1的时候代表这个伪军,使用continue跳出循环避开它。
说回前面的代码,基本每篇文章摘要右边都会附有1~3张照片,它们会被保存在列表imgs_src中,将它转成字符串并且项之间用换行符隔开,保存到Excel表格也会好看些。
再就是将这些数据保存到Excel表格了:
def saveData(datalist, savepath):
book = openpyxl.Workbook()
sheet = book.create_sheet("河北白石山六只脚游记主页Top247")
col = ('游记题名', '文章作者昵称', '作者行程/公里', '作者旅游出发时间', '作者旅游旅游时长', '展示图片')
sheet.append(col)
for i in range(0, 247):
data = datalist[i]
for j in range(0, 6): # 从0开始计算,注意去掉列头
sheet.cell(row=(i + 2), column=(j + 1), value=data[j])
book.save(savepath)从前面爬取的数据可以看到需要创建6列,分别为’游记题名’, ‘文章作者昵称’, ‘作者行程/公里’, ‘作者旅游出发时间’, ‘作者旅游旅游时长’, ‘展示图片’,还需要注意的是我们的表格行和列也是从0开始算的。
到最后的main了:
def main():
print("开始爬取......")
baseurl = 'http://www.foooooot.com/search/trip/all/1/with_pics/default/descent/?page=page_num&keyword=%E6%B2%B3%E5%8C%97%E7%99%BD%E7%9F%B3%E5%B1%B1'
datalist, pagelist = getData(baseurl)
with open('data/pagelist.txt', 'w') as pages:
pages.write('\n'.join(pagelist))
savapath = u'data/河北白石山六只脚游记主页Top247.xlsx'
saveData(datalist, savapath)这里面的baseurl变量保存的是每个主页链接的基本模式,每页不同之处就在于” page=page_num”这里,获取url的时候用1~9来替换page_num就可以了。后面是将每个副页链接换行保存pagelist.txt文件,在副页爬取的时候用。
点击运行,得到爬取的数据表格,截图:
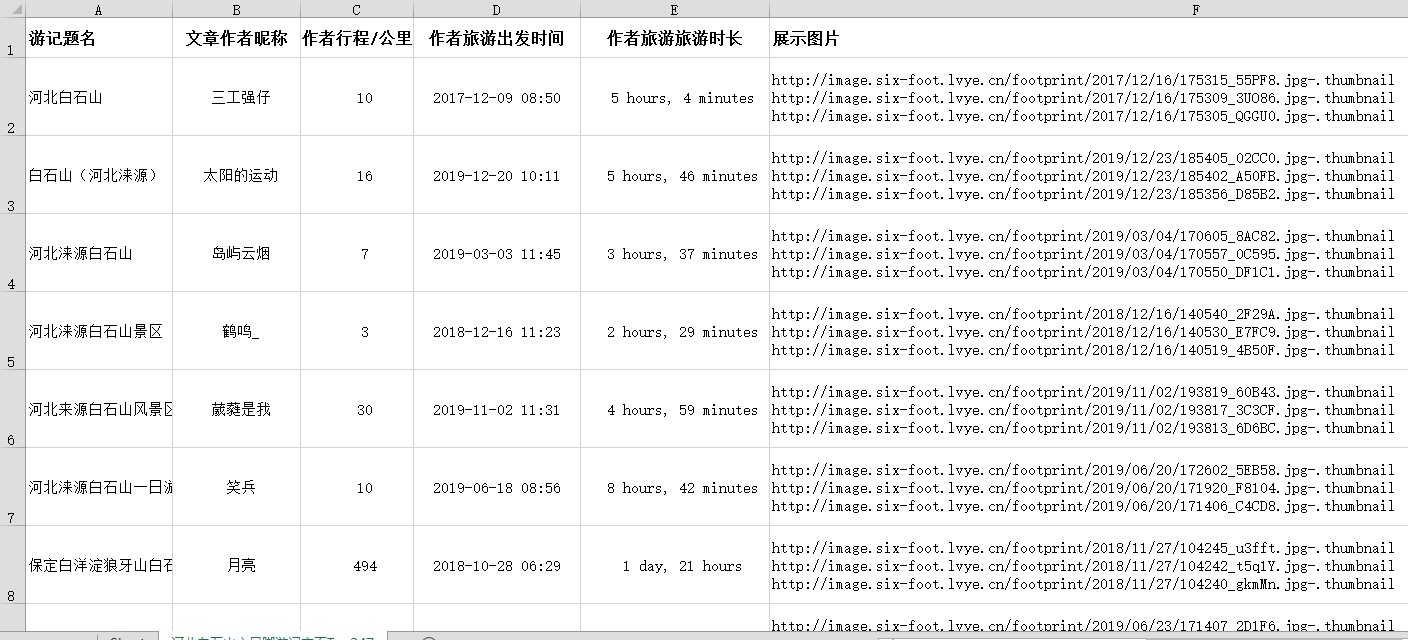
嗯,看起来还行,其实这个是我在Excel调过格式的,用代码调也看了一下资料,好像没啥用?还有一点,最后的展示图片栏,虽然保存的照片链接是换行过的,但是打开时还是会发现都在一行密密麻麻的,选择展示图片栏右键设置单元格格式–>对齐–>自动换行,舒服了:
副页爬取
主页爬取.py写完了,发现经纬度呢???好吧,每张照片拍摄地点不同,经纬度也不同,得点开每篇文章进去爬,下面是副页爬取.py。
看过了主页再理解副页就更容易了,上正则:
findLink = re.compile(r'<h1 class="title">\n*(.+\n*)</h1>') # 找到游记题名
findName_Way = re.compile(r'<a href=".+\n*" title=".+\n*">(.+\n*)</a>') # 找到文章作者昵称和旅游形式
findJourney = re.compile(r'全程(.+)公里') # 找到作者行程里数
findRise = re.compile(r'累计上升</strong>:(.+)米,<strong>') # 找到作者累计上升
findDescend = re.compile(r'累计下降:</strong>(.+)米') # 找到作者累计下降
findLow= re.compile(r'<span class="low">(.+)</span>米,<strong>') # 找到作者海拔最低
findHeight = re.compile(r'<span class="height">(.+)</span>') # 找到作者海拔最高
findSpeed = re.compile(r'</strong>(.+)公里每小时') # 找到作者最高速度
findStartTime = re.compile(r'于(.+)出发') # 找到作者旅游出发时间
findSpentTime = re.compile(r'历时(.+)\n\s+</dd>') # 找到作者旅游旅游时长
findImgSrc = re.compile(r'<span class="down_img" download="sixfoot.jpg" href="(.+)">') # 找到展示图片连接
findLongitude = re.compile(r'<span class="lat_lng" title="经纬度">(.+)</span>') # 找到展示图片拍摄经纬度
datalist = []这里的正则表达式好像是没啥需要讲的,第一个游记题名那里,有几篇同之前一样的错误,讨厌的换行符,记得加上规则。
副页爬取没有主页爬取幸运的地方在于,没有一个大的盒子足够把所要爬取的信息都囊括进去,也不是没有,有肯定有,就会包含太多混淆标签进来,分开的话文章标题、文章简介和文章照片都要分开用for循环来爬,就是这样:
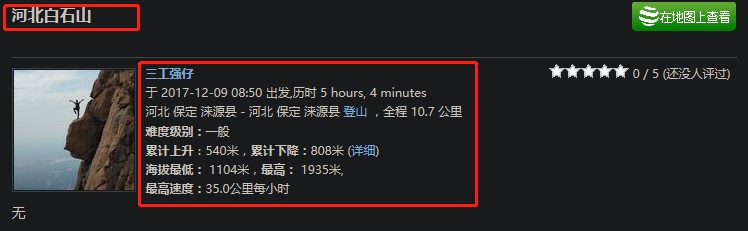

它们的盒子长这样:
<div class="trip_box trip_box_title">
<dl class="trip_box_right">
<div class="key">
在爬取之前得先把url准备好,还记得在主页爬取中保存的pagelist.txt文件,我们可以按行读取但要把链接末尾的换行符给去掉,这里用replace替换,不然连接是错误的,服务器将返回状态码500:
with open('data/pagelist.txt') as q: # 这里就用到主页爬取保存下来的文章连接了
lines = q.readlines()
for i in range(len(lines)):
lines[i] = lines[i].replace('\n', '')接下来是对这三个盒子的分别解析了,其中一三盒子有少数文章与其他文章格式不统一,比如在第三个盒子中,有些文章没有照片或者照片下面坐标,我定位到出错的其中一篇文章,就像这样:

第一个盒子那些文章是什么问题。。。我忘了,问题不大,只是极少数,用try语句把这些出错的文章信息做出修改:
for line in lines:
html = askURL(line)
soup = BeautifulSoup(html, "html.parser")
for item1 in soup.find_all('div', class_="trip_box trip_box_title"): # 找到每一个文章标题项
data1 = []
item1 = str(item1)
# print(item1)
# 这里少数也会报错,let me see see
try:
link = re.findall(findLink, item1)[0]
except:
print(item1)
data1.append(link)
for item2 in soup.find_all('dl', class_="trip_box_right"): # 找到每一个文章简介项
data2 = []
item2 = str(item2)
# print(item2)
name = re.findall(findName_Way, item2)[0]
data2.append(name)
way = re.findall(findName_Way, item2)[1]
data2.append(way)
journey = re.findall(findJourney, item2)[0]
data2.append(journey)
rise = re.findall(findRise, item2)[0]
data2.append(rise)
descend = re.findall(findDescend, item2)[0]
data2.append(descend)
low = re.findall(findLow, item2)[0]
data2.append(low)
height = re.findall(findHeight, item2)[0]
data2.append(height)
speed = re.findall(findSpeed, item2)[0]
data2.append(speed)
start_time = re.findall(findStartTime, item2)[0]
data2.append(start_time)
findMonth = re.compile('-(\d+)-') # 格式为' 2017-12-09 08:50 '
season = re.findall(findMonth, start_time)
if int(season[0]) >= 3 and int(season[0]) <= 5:
season = '春季'
elif int(season[0]) >= 6 and int(season[0]) <= 8:
season = '夏季'
elif int(season[0]) >= 9 and int(season[0]) <= 11:
season = '秋季'
else:
season = '冬季'
data2.append(season)
spent_time = re.findall(findSpentTime, item2)[0]
data2.append(spent_time)
data3 = []
for item3 in soup.find_all('div', class_="key"): # 找到每一个文章照片项
item3 = str(item3)
# print(item3)
imgs_src = re.findall(findImgSrc, item3)
longitude = re.findall(findLongitude, item3)
# 这里少数会有报错,因为那些文章没有照片或者没有经纬度坐标,嗯,坑呐
try:
imgs_info = imgs_src[0] + ' ' + longitude[0]
except:
imgs_info = '照片或经纬度信息缺失' # 放弃该篇文章照片信息
data3.append(imgs_info)
data3[0] = '\n'.join(data3)
data = data1 + data2 + data3
datalist.append(data)因为要求是出行季节数据,所以把月份换成季节了。data3=[]为什么不跟item1和item2一样写在循环里面,而写在外面呢,这是因为前面两个盒子其实都只能匹配到一个,而item3指的是照片,基本都会是有好多项的,它们都属于同一篇文章,所以还不能清空。
当一篇文章line结束,将三个盒子数据列表合成一个data = data1 + data2 + data3,当所有文章lines结束后,就得到所有文章信息列表datalist了。再后面就是数据保存到Excel表格了,基本跟主页爬取是一样的,直接上最终结果:
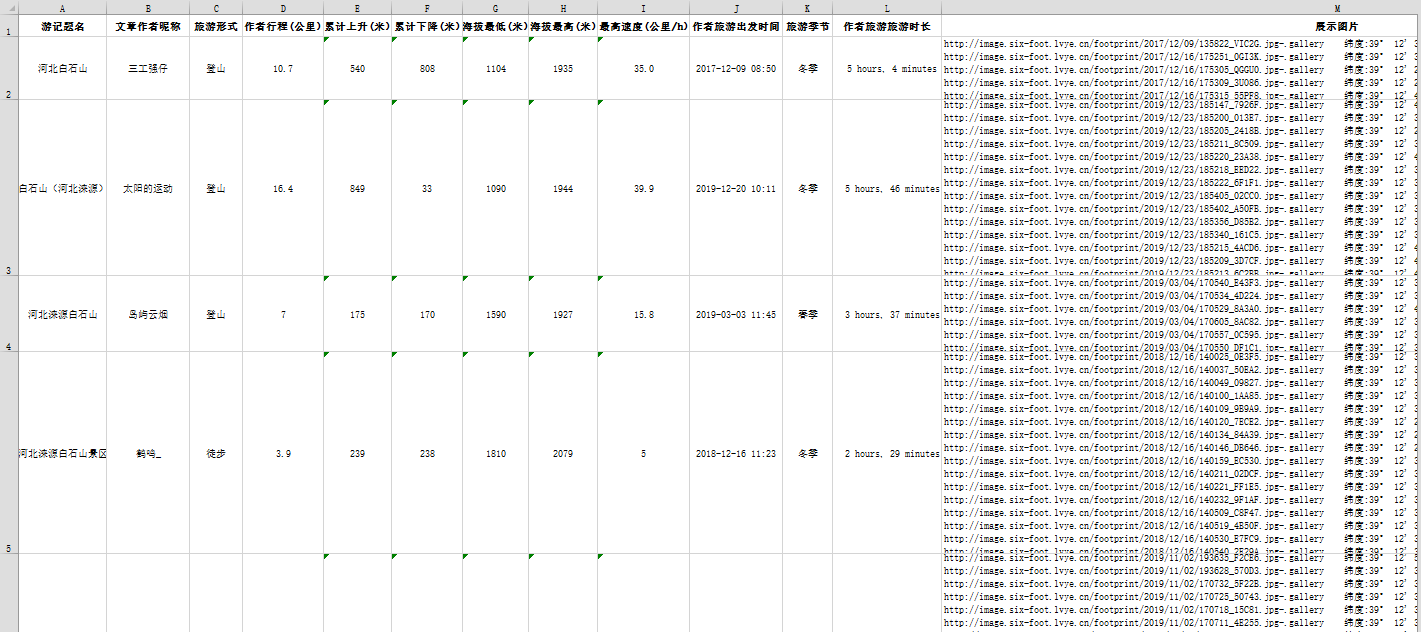
看着还行,就到这里结束吧。
或扫码搜索关注微信公众号“燕山徐一”,后台回复“白石山”获取代码。
